

Nullius in Verba #40

Unless you have been living in a cave for the past few months, you couldn’t have missed out on the maelstrom unleashed by the exponential advancements in AI. And just like most people even remotely associated with tech, I have been sucked in. Trying to keep up with the torrent of progress in the field has been a herculean challenge. Having not read papers for a while now, it’s taken me a bit of time and patience to go beyond abstracts and to understand the math behind the findings. This seminal paper on transformers was a slog for me to get through for instance. I remember taking a course on econometrics/data science back in the day and wondering where my newly acquired concepts of loss functions and stochastic gradient descent were going to be useful. Well, it looks like the time has come.
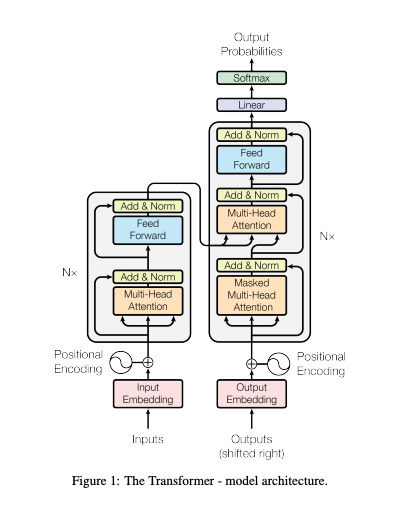
My interest is not just in the theory though (although I do love understanding things from first principles). I am mesmerized by the practical applications of the current SOTA models. In today’s edition, I am going to be talking about some of the most fascinating new models and their potential applications. The world is getting weirder by the moment. Transform (pun intended) or die.
Links of the Week
ChatGPT (and Whisper) as APIs - The most seismic announcement of the past few weeks in the space of AI. This is the proverbial shot heard around the world. (Link)
The ChatGPT model family we are releasing today,
gpt-3.5-turbo, is the same model used in the ChatGPT product. It is priced at $0.002 per 1k tokens, which is 10x cheaper than our existing GPT-3.5 models. It’s also our best model for many non-chat use cases—we’ve seen early testers migrate fromtext-davinci-003togpt-3.5-turbowith only a small amount of adjustment needed to their prompts.
Kosmos-1 - Microsoft's new Kosmos-1 is incredible. It's a new Multimodal Large Language Model (MLLM). It can understand images, text, images with text, OCR, image captioning, and visual QA. It can even solve IQ tests. (Link)

ControlNet - Is a text interface the most optimal input mode for generating images? ControlNet is based on the premise that the future of generative art needs fine-grained, multimodal control: sketches, maps, edges, lines, boundaries, user sketches, semantic segmentation, depth maps, normal maps, cartoon drawings, and instances of actual human poses. (Link)

OpenAI - Extremely instructive to read OpenAI’s short note on planning for AGI. Reading through these posts and following Sama on Twitter, it feels like OpenAI knows something about AGI that we don’t. (Link)
The first AGI will be just a point along the continuum of intelligence. We think it’s likely that progress will continue from there, possibly sustaining the rate of progress we’ve seen over the past decade for a long period of time. If this is true, the world could become extremely different from how it is today, and the risks could be extraordinary. A misaligned superintelligent AGI could cause grievous harm to the world; an autocratic regime with a decisive superintelligence lead could do that too.
Generative UI - Galileo AI is the first major high-profile product based on using natural language prompts to generate high-fidelity designs (editable in Figma). I have a feeling they won’t be the last (your move, Adobe). (Link)

Toolformer - Toolformer is a self-supervised language model that can use external tools (e.g., calculator, Q&A, search engines, translation, calendar) via simple APIs to improve zero-shot performance across a variety of downstream tasks. (Link)
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.
VALL-E - VALL-E is, in my admittedly limited view, one of the best text-to-speech and speech synthesis models out there. A combination of chatGPT, Whisper, and Vall-E in theory can deliver a conversational voice assistant of impeccable quality (like the one shown in the movie HER). (Link)
Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis.
Happy reading!